

Aujourd’hui quelques géants de l’intelligence artificielle tels qu’OpenAI, Google et Anthropic dominent le marché des modèles IA. De la même manière que Google est devenu le moteur de recherche de référence, ChatGPT est rapidement devenu le moteur de réponse par défaut de la plupart des usagers. Cependant, ces services sont souvent limités par des quotas d’utilisation, des abonnements, des tokens à surveiller, des contraintes de confidentialité, etc. C’est là que l’IA locale entre en jeu.
Pourquoi faire tourner un LLM en local sur son PC ?
Utiliser un LLM directement sur sa machine présente de nombreux avantages, qu’il serait dommage d’ignorer :
- 🔒 Confidentialité garantie — Vos données ne quittent jamais votre ordinateur. Idéal pour les projets sensibles ou les documents professionnels.
- ♾️ Zéro limite d’utilisation — Pas d’abonnement, pas de quotas, pas de token à surveiller. Vous utilisez l’IA autant que vous voulez.
- ⚡ Réactivité immédiate — Les réponses sont souvent plus rapides qu’avec des modèles en ligne grâce à l’absence de latence réseau.
- 💸 Investissement unique — Un bon GPU et c’est une IA gratuite à vie, sans dépendance à des services externes.
- 🛠️ Personnalisation totale — Possibilité d’entraîner ou d’adapter le modèle à votre propre base de connaissances.
- 🛜 Utilisable hors connexion — Fonctionne même sans Internet : pratique en mobilité ou en environnement isolé.
- 🧠 Contrôle complet de l’infrastructure — Vous choisissez le modèle, la version et son comportement.
- 🔗 Intégration locale simplifiée — L’IA peut interagir directement avec vos fichiers, outils et workflows de développement.
IA locale avec Ollama
Qu’est-ce qu’Ollama ?
Ollama est un outil open-source permettant d’exécuter des modèles de langage (LLM) open source comme Deepseek, Llama ou encore Gemma localement sur son ordinateur (macOS, Windows et Linux).
À travers un outil en ligne de commande (CLI) intuitif, il facilite ainsi :
- 📦 La gestion de modèles (installation, suppression, etc.)
- 🚀 L’exécution
Ollama se distingue par sa capacité à fonctionner entièrement hors ligne, offrant ainsi une alternative plus privée et économique aux services cloud.
Configuration requise
Il est important de noter que si tout le monde peut utiliser ChatGPT confortablement c’est parce que l’IA tourne sur des serveurs cloud d’une grande puissance, bien plus puissants que notre PC.
Si vous envisagez de faire tourner des modèles IA sur votre ordinateur, il est important d’être attentif à ce que les modèles en question aient un nombre limité de paramètres. En effet, plus un modèle a de paramètres, plus il consomme de ressources.
Côté configuration, il n’y a pas de règle stricte quant à la configuration requise pour votre PC car cela dépend du modèle que vous souhaitez utiliser. Mais on recommande la plupart du temps d’avoir un PC un minimum performant, et d’au moins disposer de :
- 8 Go de RAM (16 Go recommandé)
- CPU seul : suffisant pour les petits modèles
- GPU en complément : fortement recommandé (avec CUDA) pour faire tourner des modèles un peu gros (
≥ 7B). - Stockage : les petits modèles font généralement entre 1 à 10 Go
3 étapes pour faire tourner une IA en local avec Ollama
📥 1. Télécharger et installer Ollama
Pour installer Ollama, il suffit de suivre les instructions adaptées à votre système d’exploitation sur le site officiel : https://ollama.com/download.
📦 2. Télécharger un modèle
Pour utiliser un modèle, il faut d’abord le télécharger. Ollama permet de télécharger un modèle en ouvrant un terminal et en tapant la commande suivante :
ollama pull <nom-du-modele>On pourrait par exemple remplacer <nom-du-modele> par llama2 pour installer le modèle LLaMA 2 de Meta.
🚀 3. Exécuter un modèle (CLI)
Une fois installé, un modèle peut être exécuté en tapant la commande suivante :
ollama run <nom-du-modele>Si le modèle n’est pas déjà téléchargé, Ollama va préalablement exécuter un ollama pull et le stocker localement.
Une invite de commande s’ouvre alors et permet de discuter avec l’IA, à la manière des chat IA en ligne comme ChatGPT.
Pour plus d’informations sur l’usage des commandes ollama (supprimer un modèle, lister les modèles, etc.), je vous invite à consulter la CLI Reference Ollama.
Bonus : Utiliser une interface graphique (GUI)
Il existe aussi des interfaces graphiques (GUI) permettant d’interagir avec Ollama. Et il faut bien l’avouer, elles sont plus agréables à utiliser qu’un terminal !
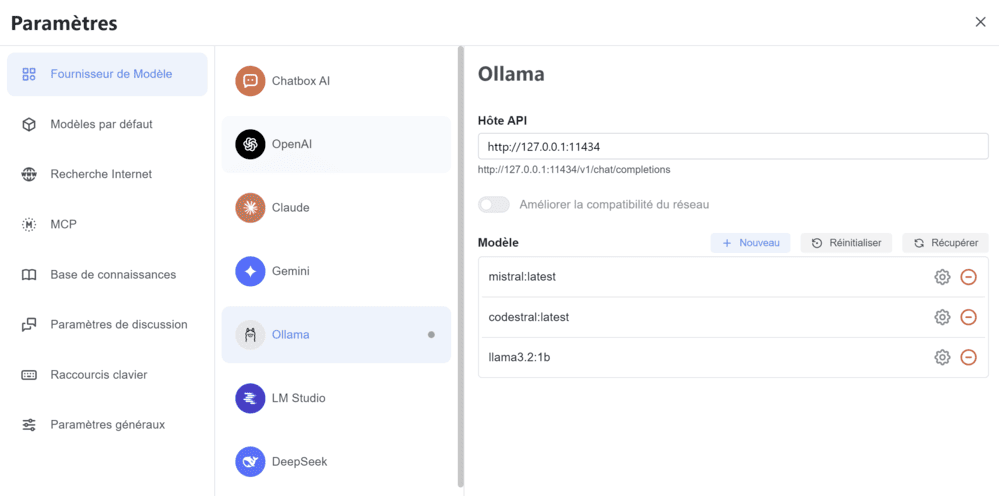
J’utilise pour ma part Chatbox AI qui permet d’utiliser les modèles locaux installés via Ollama pour interagir avec l’IA.
Les modèles installés localement peuvent ainsi facilement être activés dans le chat via l’onglet Fournisseur de Modèle > Ollama. 👇
Utiliser des modèles Ollama dans une app
Ollama expose une API locale vous permettant d’interagir avec l’IA au sein d’une application ou d’un script via une requête HTTP envoyée à l’adresse http://localhost:11434/api.
Interagir avec API Ollama (curl)
curl http://localhost:11434/api/chat -d '{
"model": "llama3.1",
"messages": [{
"role": "user",
"content": "Propose-moi une recette de cuisine"
}],
"stream": false
}'Interagir avec API Ollama (JavaScript)
Installer la librairie JS Ollama :
npm i ollamaUtilisez-la dans votre code :
import ollama from 'ollama'
const response = await ollama.chat({
model: 'llama3.1',
messages: [{ role: 'user', content: 'Propose-moi une recette de cuisine' }],
})
console.log(response.message.content)Interagir avec API Ollama (Python)
Installer la librairie Python Ollama :
pip install ollamaUtilisez-la dans votre code :
from ollama import chat
from ollama import ChatResponse
response: ChatResponse = chat(model='llama3.1', messages=[
{
'role': 'user',
'content': 'Propose-moi une recette de cuisine',
},
])
print(response.message.content)Faire tourner l’IA en local, c’est reprendre le contrôle grâce à l’open source : plus de dépendance, plus de limites, juste votre puissance de calcul.